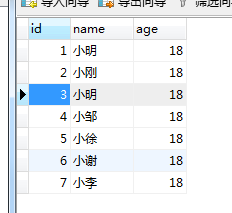
you probably mean that if the number of columns is the same as the number of indexes, the index scan speed is the same as the full table scan speed.
however, it is absolutely different.
to put it simply, the index is a tree structure, the data in each node is ordered, the nodes in the same layer are ordered, and the whole data structure is highly ordered, so it does not need to traverse all the index nodes to find the data, or make sure there is no target data.
ordering accelerates search speed, which you can compare to binary search. The data of binary search is ordered, and it can locate the target data without traversing all the nodes in the array.
if you are interested in the principle of Mysql index, you can take a look at data structure and algorithm behind MySQL index
this question is a bit difficult to answer, one is that MyISAM and InnoDB use B+Tree , not B-Tree, so the question picture is not correct; the other is that it does not specify whether name is a primary key index or a general index, if it is a general index, whether it is MyISAM or InnoDB, the scanning index performance is better.
now let's constrain the condition, assume that name is the primary key, compare the difference between scanning all indexes and all data, and assume that all data is not in memory.
MyISAM
The
MyISAM engine uses B+Tree as the index structure, and the data domain of the leaf node stores the address of the data record, that is, the index and the data are separate.
therefore, scanning the entire index area performs better than the data area
InnoDB
The data file of
InnoDB is itself an index file. In InnoDB, the table data file itself is an index structure organized by B+Tree, and the data domain of the leaf node of this tree keeps the complete data record. The key of this index is the primary key of the data table, and the InnoDB table data file itself is the primary index.
therefore, scanning the entire index area is the same as the data area
this article is really good the data structure and algorithm behind the MySQL index
The number of
columns is the same as the number of indexes, the speed of scanning indexes and the speed of full table scanning?