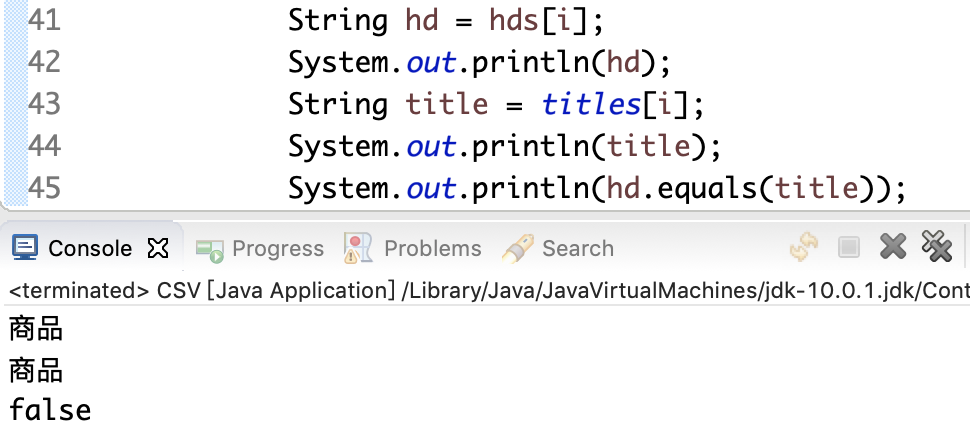
this question is named goods
Why is it followed by false
this question is named goods
Why is it followed by false
your two strings are actually the following a / b array. Because the console is utf-8 encoded, it looks the same
.char[] a = new char[3];
a[0] = '\uFEFF';
a[1] = '';
a[2] = '';
System.out.println(String.valueOf(a));
char[] b = new char[2];
b[0] = '';
b[1] = '';
System.out.println(String.valueOf(b));may be invisible characters such as spaces.
1. There are invisible characters in the data source such as\ r,\ n,\ tand so on
2. The current equals method has been overridden
static void printUTF8Bytes(String s) {
try {
byte[] b = s.getBytes("utf-8");
for(byte c : b) {
System.out.print(Integer.toHexString(c&0xff));
}
System.out.println();
} catch (java.io.UnsupportedEncodingException e) {
e.printStackTrace();
}
} use this printUTF8Bytes method to output the UTF-8 codes of hd and title.
I encountered once that I read out the contents of a txt file and compared it in the code. It was very simple, but in the end, all the lines in it matched. Except for the first line. Finally, debug looked. As a result, the beginning of the first line is inexplicably stuffed with a \ uFEFF
contents of the file
char\uFEFF
\uFEFF
debug

so finally, in order to achieve my goal, I abandoned the first line and started reading from the second line, with a space in the first line or whatever I could write, which solved the problem at that time
after Baidu, it seems that the notepad editing tool that comes with windows will add 0xefbbbf (hexadecimal) characters at the beginning of each file when saving UTF-8 files (describe the deployment of javaweb project to tomcat, summary of problems in modifying configuration files )
thx, for reference only
The horizontal coordinates of echarts are not specifically marked, and the X coordinates do not have a grid to indicate. Here is a figure that specifies . js * * createChartSix() { this.$http .get(this.$api.dataChart) .then(rsp => { ...
sincerely ask for advice: < hr > I want to use node as the background to build a video streaming server. The front end is similar to Youku VOD. It can record the playback node function, and load the progress bar at any point (starting from the c...
I need to implement in a chained promise function, any function error in the middle terminates the program, and can catch the error function, and then perform different operations according to different error functions. How can the following code be imp...
I would like to ask what is wrong with this code. Thank you for your answers. ...
is doing a question on Niuke.com. I encounter a problem: to achieve the function callIt, after the call meets the following conditions 1, the returned result is the result after calling fn 2, and the call parameter of fn is all the parameters after th...
A timing examination system is triggered if the click event is triggered within 5 seconds, and if it is not triggered, the system marks the correct answer at the end of the countdown. How to implement ...
description: a regular match is given to the content of an input box, and the matching content is the product activation code. looks like this: "0C31-0B81-BB32-3094-0C31-0B81-BB32-3094 " Code: $( -sharplicenseCode ).keyup(function () { le...
1. The custom event triggers the click event of .cpcstartrefresh, but triggers 2 click events each time 2. The code is as follows: window.onmessage = function (e) { create an event object, var myEvent = document.createEvent( Event ); m...
I configured the MIME type of the file with the amr suffix in the apache configuration as application ms-download, Why it is a garbled page when opening a file in amr format using window.open in chrome, while a file in amr format can be successfully dow...
I got a set of data, which is to choose the type of question. How can I tell if I have chosen the right one answera: "Olympic Games " answerb: "Asian Games " answerc: "Paralympic Games " answerd: "University Games " id: "1772 " question: "f...
read a number, such as 521 change this number to 0521 but put it into four div separately, how to realize it? 0 < div > 5 < div > 2 < div > 1 < div > ...
react projects cannot save store? using redux, data index.js ReactDOM.render( <Provider store={store}> <Router > < Provider>, document.getElementById( root )) registerServiceWorker() actions export const SET_USER = ...
FileInputStream fis = new FileInputStream (); int t = fis.read; how to see that the read method returns a number of type int? The source code is not implemented? ...
prepare to start an app background development. The basic framework is spring, spring mvc, mybatis (write), jdbctemplate (read). in order to deal with the problem of high concurrency in the future, what designs or technologies are best carried out in ...
how to find all the NA characters in a HMLT page and replace it with "and invalid " with native JS ...
...
suppose there are only a.js and b.js (only two js and nothing else) b.js export A variable is used for a.js can you directly use import and export without using packaging and compilation tools such as webpack or babel can it be achieved with the h...
such as the question, with asynchronous functions also deal with data, but how to feedback to the foreground? It would be nice to give some ideas ...
do the gods have plug-ins for uploading attachments in the mobile version that can also be uploaded more than one? ...
what does the code circled in the following picture mean? ...



